
I’ve made a couple of projects that play audio alerts using a dfplayer and MP3 files. One in a clock that plays announcements and the other a countdown timer. When I did those, I used onlinetonegenerator.com to convert text to speech. I liked the voices but it doesn’t have an option to save the audio as an MP3 file. I ended up using Audacity to record the computers audio. It worked but was very tedious. Since then, I’ve been looking for a simpler way.
The important criteria in a text to speech service for me is:
- Ability to enter text, listen to the converted audio in the browser and then download it as an mp3 file.
- Sufficient audio quality.
- Volume level ok.
- Suitable lead in and end dead time to allow multiple files to be played in sequence with the result sounding as a smooth sentence. For example these four files together; “The time is”, “eleven”, “thirty two”, “am”.
- A suitable voice. They don’t all have the same voices. I prefer some more than others.
- Free or good value.
- Ability to change speed, pitch and emphasis a bonus.
Here are a few I’ve looked at.
Online Tone Generator (onlinetonegenerator.com/voice-generator.html)
This is the first one I used. Its:
- Free.
- Has a good range of voices; mostly Google, plus a few Microsoft ones I presume are built into my Windows PC. I particularly like Google français.
- Lots of other audio tools, including; noise generator, sweep generator, DTMF signals.
- But, no MP3 download.
Update 27/12/22: As noted on their page “Different browsers and operating systems have different voices”. I’ve only tested with a Windows 10 PC and found that I only had the option to select Google voices (plus some Micrsosoft ones) when using Chrome. Firefox only had some Microsoft ones. Edge only had Microsoft ones, which included ones that were available in Chrome and Firefox plus a lot of their ‘natural’ voices. So, try different browsers if you want to see if you can access other voices.
From Text To Speech (fromtexttospeech.com)
I briefly looked at this one. It is:
- Free.
- Has a 50 000 character limit per file.
- I’m unable to listen in browser. No play button displays until a file is created and then the player presented appears to use flash and is blocked by my browser. The file can be downloaded and used.
- MP3 download.
- Different speed and voices.
TTSMP3 (ttsmp3.com)
This is the one that I am intending to use in my next project. Lots of features, MP3 file output and a fair amount of free usage. It is:
- Free for 3,000 characters (~375 words) per day.
- Lots of different voices.
- Supports speed, pitch and other effects using tags.
- Multiple voices can be used in the one piece of text by using tags.
- MP3 file download.
TTSMP3 uses Amazon Polly and comes with quite a few voices and features. Additional effects can be used by using tags in your text. More info about tags is available on this Amazon page.
Here is an example of the voices.
That audio file was created by pasting the text below into the converter. Beware if you do this it will use up most of your daily 3000 character limit.
[speaker:Zeina] Hi, I'm Arabic Zeina
[speaker:Russell] Hi, I'm Russell Australian English Russell
[speaker:Nicole] Hi, I'm Australian English Nicole
[speaker:Camila] Hi, I'm Brazilian Portuguese Camila
[speaker:Ricardo] Hi, I'm Brazilian Portuguese Ricardo
[speaker:Vitória] Hi, I'm Brazilian Portuguese Vitória
[speaker:Emma] Hi, I'm British English Emma
[speaker:Amy] Hi, I'm British English Amy
[speaker:Brian] Hi, I'm British English Brian
[speaker:Chantal] Hi, I'm Canadian French Chantal
[speaker:Enrique] Hi, I'm Castilian Spanish Enrique
[speaker:Lucia] Hi, I'm Castilian Spanish Lucia
[speaker:Conchita] Hi, I'm Castilian Spanish Conchita
[speaker:Zhiyu] Hi, I'm Chinese Mandarin Zhiyu
[speaker:Mads] Hi, I'm Danish Mads
[speaker:Naja] Hi, I'm Danish Naja
[speaker:Ruben] Hi, I'm Dutch Ruben
[speaker:Lotte] Hi, I'm Dutch Lotte
[speaker:Céline] Hi, I'm French Céline
[speaker:Léa] Hi, I'm French Léa
[speaker:Mathieu] Hi, I'm French Mathieu
[speaker:Vicki] Hi, I'm German Vicki
[speaker:Marlene] Hi, I'm German Marlene
[speaker:Hans] Hi, I'm German Hans
[speaker:Karl] Hi, I'm Icelandic Karl
[speaker:Dóra] Hi, I'm Icelandic Dóra
[speaker:Aditi] Hi, I'm Indian English Aditi
[speaker:Raveena] Hi, I'm Indian English Raveena
[speaker:Carla] Hi, I'm Italian Carla
[speaker:Giorgio] Hi, I'm Italian Giorgio
[speaker:Bianca] Hi, I'm Italian Bianca
[speaker:Takumi] Hi, I'm Japanese Takumi
[speaker:Mizuki] Hi, I'm Japanese Mizuki
[speaker:Seoyeon] Hi, I'm Korean Seoyeon
[speaker:Mia] Hi, I'm Mexican Spanish Mia
[speaker:Liv] Hi, I'm Norwegian Liv
[speaker:Ewa] Hi, I'm Polish Ewa
[speaker:Jan] Hi, I'm Polish Jan
[speaker:Maja] Hi, I'm Polish Maja
[speaker:Jacek] Hi, I'm Polish Jacek
[speaker:Inês] Hi, I'm Portuguese Inês
[speaker:Cristiano] Hi, I'm Portuguese Cristiano
[speaker:Carmen] Hi, I'm Romanian Carmen
[speaker:Maxim] Hi, I'm Russian Maxim
[speaker:Tatyana] Hi, I'm Russian Tatyana
[speaker:Astrid] Hi, I'm Swedish Astrid
[speaker:Filiz] Hi, I'm Turkish Filiz
[speaker:Joey] Hi, I'm US English Joey
[speaker:Kimberly] Hi, I'm US English Kimberly
[speaker:Salli] Hi, I'm US English Salli
[speaker:Ivy] Hi, I'm US English Ivy
[speaker:Matthew] Hi, I'm US English Matthew
[speaker:Kendra] Hi, I'm US English Kendra
[speaker:Joanna] Hi, I'm US English Joanna
[speaker:Justin] Hi, I'm US English Justin
[speaker:Miguel] Hi, I'm US Spanish Miguel
[speaker:Lupe] Hi, I'm US Spanish Lupe
[speaker:Penélope] Hi, I'm US Spanish Penélope
[speaker:Gwyneth] Hi, I'm Welsh Gwyneth
[speaker:Geraint] Hi, I'm Welsh English Geraint
Comparisons
Compared with the original audio files that I created by using Audacity to record the PC audio and onlinetonegenerator.com, ttsmp3.com had lower volume. I may have had the record level a bit high when I used Audacity so not sure that the ttsmp3 level is too low.
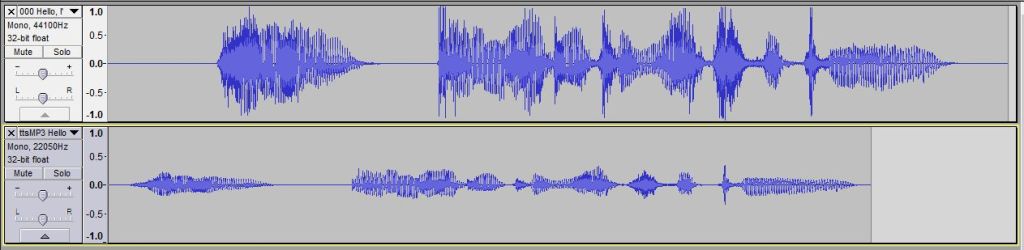
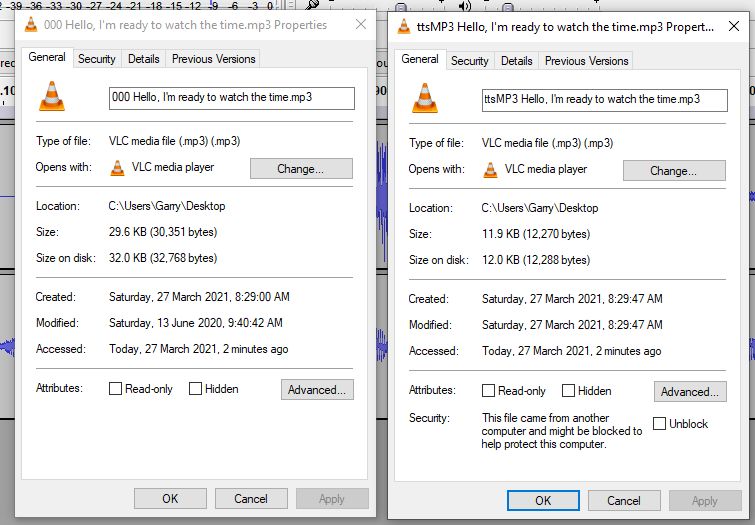
The bit rate is also different, with the Audacity ones higher. That’s probably because I unnecessarily chose a higher bitrate in Audacity. TTSMP3 was 48kbs.

And that affected the file size. The TTSMP3 is much smaller.
Here are a couple of examples for comparison. For each I created four separate files and then joined them together to see how smooth the transition was. The four files were “The time is”, “11”, “32”, “AM”. I had to be a bit creative with the AM for French Celine as it was pronounced as “am”.
onlinetonegenerator.com Voice is Google français. I like this voice. It has added a lot of character to my speaking clock.
ttsmp3.com Voice is French Celine. It was much easier to create and the timing between files is ok, but the voice doesn’t have the same character to the one above in my opinion
ttsmp3.com This is British Amy. This was just for comparison to see how the same text would sound with an English voice.
Do you have other methods? Let me know.
Update 13/4/2021: I have added a post with info about how to increase the audio level in a batch of files Batch processing files with Audacity
